
Getty Images/iStockphoto
Wie künstliche Intelligenz das Testen von Software verändert
Wird künstliche Intelligenz menschliches Fachwissen bei Softwaretests überflüssig machen? Zumindest wird KI-Technologie zu mehr und anderen Softwaretests führen.

Es ist eine Frage, die viele Softwareprofis heute beschäftigt: Wann wird künstliche Intelligenz Softwaretests überflüssig machen? In fünf Jahren? In zehn Jahren? Oder doch erst in zwanzig?
Um die Frage zu diskutieren, wie KI-basierte Softwaretests Jobs und Prozesse verändern, müssen wir uns zunächst überlegen, welche Teile des Testens künstliche Intelligenz (KI) überhaupt abdecken kann. Denn darauf kommt es letztendlich an – viel mehr noch als darauf, ob KI irgendwann ganz die Oberhand gewinnt.
Überraschend ist in dem Kontext auch, dass preisgünstigere Tests zu einer erhöhten Nachfrage führen können. Dazu aber gleich mehr.
Geringere Kosten = mehr Aufkommen
In den 1860er Jahren gelang es England, die Kosten für Kohle drastisch zu senken. Da durch die billigere Kohle die Menschen eher bereit waren, mehr Kohle zu verfeuern, führte dies zu einem Anstieg des Kohleverbrauchs. Gleichzeitig bedeutete die kostengünstigere Kohle, dass Projekte, die bisher als unwirtschaftlich galten, zum Beispiel eine Eisenbahnlinie von Punkt A nach Punkt B, plötzlich zu tragfähigen Geschäftsmöglichkeiten wurden. Dieses Phänomen ist als Jevons Paradoxon bekannt geworden.
Ähnliches geschah bei der Softwareentwicklung. Mit der zunehmenden Leistungsfähigkeit der Programmiersprachen wuchsen die Anwendungen schnell über die profane Lohn- und Gehaltsabrechnung und das Geschäftsberichtswesen hinaus. Heute kann jeder in kurzer Zeit eine Anwendung schreiben, die zum Beispiel den Standort seines Autos verfolgt. Eines Tages könnte dieses Hobby zu einem lukrativen Nebenjob werden.
Künstliche Intelligenz (KI) und Machine Learning (ML) bleiben bei dieser Entwicklung nicht außen vor. Wenn Daten in großem Umfang verfügbar und die Tools allgemein zugänglicher werden, können Projekte, die früher unmöglich zu bewältigen oder zu teuer schienen, vernünftig und praktisch durchführbar sein. Das bedeutet, dass wir mehr von KI- und ML-Anwendungen sehen werden.
Diese Projekte müssen getestet werden. Das Aufkommen von KI und maschinellem Lernen wird also zu mehr Tests – oder zumindest zu anderen Tests – und nicht zu weniger Tests führen.
Teile, nicht das Ganze
Auf einer Konferenz im Jahr 2004 drehte sich alles um testgetriebene Entwicklung und das Ende des nicht-technischen Testers. Fünfzehn Jahre später sind wir bei einer nuancierteren Position angekommen – nämlich einer Diskussion darüber, welche Teile des Testprozesses automatisiert werden können.
Ähnlich verhält es sich mit KI und Machine Learning. Man kann nicht einfach KI auf Software loslassen und sagen: Finde heraus, ob das funktioniert. Man muss immer noch festlegen, was es bedeutet, dass etwas funktioniert. Nur dann kann das Test-Tool feststellen, ob die Erwartungen erfüllt werden können.
In seinem legendären Black-Box-Softwaretestkurs stellt der Professor Cem Kaner ein Beispiel für das Testen eines Open-Source-Tabellenprodukts vor. Wenn die Geschäftsregel, eine Zelle zu bewerten, darin besteht, die Mathematik genauso anzuwenden wie Microsoft Excel, kann eine Zufallsformel generiert werden. Dann können sowohl Excel als auch die zu testende Software die Formel auswerten und es kann gezeigt werden, dass sie übereinstimmen.
Um diese Strategie zu nutzen, benötigt der Tester die richtige Antwort – und damit Microsoft Excel. In einigen Szenarien ist es möglich, KI dazu zu bringen, als dieses Orakel zu agieren. KI ist dann die Methode, mit der überprüft wird, ob ein Fehler tatsächlich ein Fehler ist. Selbst in diesem Fall wird KI nicht in der Lage sein, Probleme bei Sicherheit, Benutzerfreundlichkeit oder Leistung zu finden.
Jede seriöse Beschäftigung mit KI und Machine Learning muss sich also fragen, wo man die Technologie einsetzen kann. Lassen Sie uns einen genaueren Blick darauf werfen.
Szenarien für Softwaretests mit KI
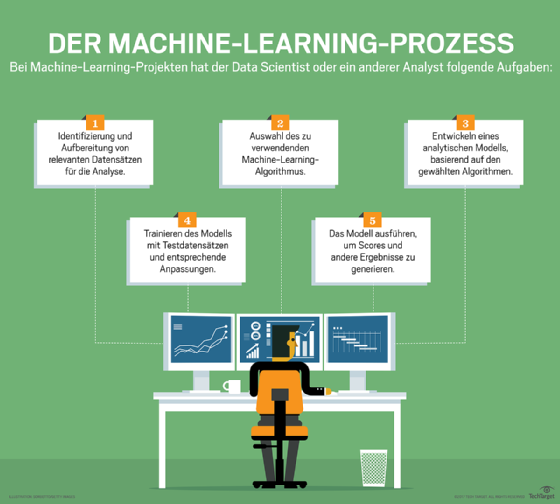
Eine strenge Definition von künstlicher Intelligenz beschreibt diese als die Nutzung von abstrakter Logik, um menschliche Intelligenz zu simulieren. Mit dieser Definition wäre schon unser Tabellenkalkulationsvergleich künstliche Intelligenz. Wenn die meisten Menschen den Begriff KI verwenden, meinen sie jedoch in der Regel die Fähigkeit, auf der Grundlage von Daten zu lernen.
Im besten Fall wird es einige hunderttausend Beispiele für Trainingsdaten geben, kombiniert mit der richtigen Antwort. Sobald die Software die Beispiele einliest, kann sie ihren Lernalgorithmus starten, die Beispiele erneut durchlaufen, und versuchen, die Antwort vorherzusagen. Diese vergleicht sie mit den Beispielantworten und wiederholt im Fall eines schlechten Matching den Lernprozess – so lange, bis die Vorhersagen gut genug sind.
Dieser Ansatz bietet einige direkte Anwendungen für das Softwaretesten mit KI.
Automatisierte Orakel von Expertensystemen: Mit genügend Beispielen können Machine-Learning-Systeme die Antwort vorhersagen. Nehmen wir als Beispiel eine Website, die körperliche Symptome als Daten entgegennimmt und als Output eine medizinische Diagnose stellt. Der Algorithmus wird getestet, indem man vergleicht, was Mediziner diagnostizieren würden, und was die Software diagnostiziert. Das Erstaunliche an diesem Ansatz ist, dass die Testsoftware irgendwann das Verhalten der Software nachahmen wird, die sie testet, da sie die richtige Antwort für den Vergleich finden muss.
Dies führt zur Möglichkeit eines selbstkorrigierenden Systems. Das heißt, drei verschiedene KI-Sets, denen man alle die gleichen Symptome gibt und die alle gebeten werden, die richtige Antwort vorherzusagen, werden um ein viertes System ergänzt. Dieses vierte System vergleicht die Antworten, um sicherzustellen, dass sie übereinstimmen. Die NASA hat diesen Ansatz zum Beispiel verwendet, um ihre Softwaremodelle zu überprüfen. Der Hauptunterschied besteht darin, dass man diese Technologie dazu bringen muss, aus echten Daten zu lernen – und nicht aus Algorithmen, die von Menschen programmiert wurden.
Generierung von Testdaten: Mit Hilfe von Live-Testdaten, zum Beispiel Kundendaten, können reale Bedingungen ermittelt werden. Dies bietet die besten Chancen, echte Probleme zu finden. Andererseits können Tests mit echten Daten unangenehm oder sogar ein Sicherheitsrisiko sein. Im Falle von persönlichen Daten oder Gesundheitsinformationen verbieten Gesetze sogar, dies zu tun. Die Verwendung von falschen Daten birgt das Risiko, dass umfangreiche Fehlerkategorien fehlen, die Sie mit echten Daten leicht hätten finden können.
Das ist das Paradoxon der Testdaten. Machine Learning und KI können reale Daten – Kundendaten, Protokolldateien und dergleichen – betrachten und dann Daten erzeugen, die nicht real sind – aber real genug, um wichtig zu sein. Dies können gefälschte Kundeninformationen, Kreditkarteninformationen, Bestellungen, Versicherungsansprüche und so weiter sein.
Sobald Sie die Testdaten generiert haben, möchten Sie möglicherweise die richtige Antwort finden – zum Beispiel, ob die gefälschte, generierte Forderung bezahlt werden soll? Bei einem ausreichend großen Datensatz kann das maschinelle Lernen auch hier Abhilfe schaffen.
Fehlerkorrektur: Eines der größten Probleme bei der langfristigen Durchführung von End-to-End-Tests ist, dass sich die Software ändern wird. Schließlich ist es die Aufgabe eines Programmierers, Software nach und nach zu verbessern. Die Software hat also gestern irgendetwas gemacht und macht heute etwas anderes – was die Testsoftware als Fehler registriert. Das einfachste Beispiel dafür ist ein UI-Element, das an eine andere Stelle platziert oder modifiziert wurde. Plötzlich kann die Testsoftware den Such-Button oder das Warenkorbsymbol nicht mehr finden, nur weil es sich an anderer Stelle befindet oder sich das Aussehen geändert hat.
Es gibt bereits Werkzeuge, die raten können und versuchen, durch die Benutzeroberfläche einen Weg zu finden, auch wenn sie sich geändert hat. Andere, einschließlich test.ai, können lernen, Dinge wie das Icon eines Warenkorbs zu erkennen, auch wenn das Bild anders aussieht. Dies ist nicht anders als bei Facebook oder einer Foto-App, die Gesichter erkennt.
Generierung von Testideen: Oftmals stehen wir beim Testen vor einem kombinatorischen Problem: Wir haben zehn mögliche Dinge für eine Bedingung, zehn für eine andere, zehn für eine dritte, und zehn für eine vierte, was zu 10.000 möglichen Testideen führt. Wenn die Automatisierung nicht wirtschaftlich ist, werden auch nicht alle 10.000 getestet. Das Testen von nur 40 (All Singles) ist wahrscheinlich nicht genug. Es gibt Werkzeuge, um die höchstmögliche Abdeckung mit der geringstmöglichen Anzahl von Tests zu erzeugen, was manchmal als paarweises Testen bezeichnet wird. Das Finden dieser Paare erfordert kein Lernen, aber es ist eine Art künstliche Intelligenz.
Viele preiswerte Online-Kurse sind verfügbar, die Machine Learning unterrichten, und viele Leute empfehlen, einfach einzutauchen. Aber ist das der klügste Ansatz?
Die Herausforderung beim Softwaretesten mit KI und Machine Learning besteht darin, die Anwendungsfälle zu finden, die tatsächlich funktionieren – zusammen mit den Orakeln. Die Bestandteile davon sind einfach: die Testidee, die Daten und das erwartete Ergebnis. KI kann in all diesen Fällen helfen, aber sie kann sie nicht magisch und nahtlos zusammenfügen. Für das nächste Jahrzehnt – oder auch länger – wird diese Arbeit die Arbeit des menschlichen Testers bleiben.





